
Microsoft just integrated RAG into their AI-based Search Engine, Let’s explore what is RAG.
Microsoft just built a tech to compete with Google and OpenAI. This article explains the tech in detail

Here is what you can expect from this article:
Why do we need RAG?
How RAG will give Microsoft’s Search Engine (Bing) an edge over other search engines?
How do RAG work and their architecture?
I have tried to write complex terms while keeping it as simple as possible. So, that you’ll be able to get the most out of it. Read the article till the end. If you find this article insightful and you haven’t joined Damn Dev, join us now here:

We all have witnessed how these Generative AI and LLMs have evolved in recent times. All these models have brought a drastic change in AI & ML across industries and sectors. Especially LLMs (Large Language Models) like ChatGPT, Bard, etc. have an immense amount of popularity among the masses and the AI Community. All these popularity and impact resulted in incredible advancements in the field of NLP (Natural Language Processing), text generation, and understanding of the text. The best example would be that these text generation models like ChatGPT used to be a prompt-to-output model and now it’s becoming a text-to-output model. It makes it more accessible and eliminates the need for prompt engineering. The paradigm shift is easily visible.
Despite all the commendable capabilities of these LLMs like text generation, article summarization, question answering, etc., it has still have some drawbacks These models can sometimes produce an output that can be inaccurate, outdated, or nonsensical. Even you cannot rely on the output generated by these LLMs. Mostly this happens when you enquire about something recent or the specific data is not present in the model’s training dataset. You must have seen this warning while using OpenAI’s ChatGPT. This phenomenon of generating inaccurate outputs is termed as AI hallucination1.

or this on Google’s Bard

But, What is RAG (Retrieval Augmented Generation)?
Retrieval Augmented Generation (RAG) is an emerging Natural Language Processing technique used to get rid of the above-mentioned nagging issue of AI hallucination. It combines the power of retrieval-based and generation-based approaches. RAG provides LLMs with the access to most accurate and up-to-date information possible in real time. It asks the LLM model to consider this additional info in its response by providing the most recent and relevant data. So, it can overcome the drawbacks of conventional LLMs by generating high-quality and contextually relevant responses by leveraging both pre-existing knowledge and the ability to generate new information.
The core idea behind RAG is to utilize a retrieval-based model to retrieve relevant documents or passages from a large corpus of text. These retrieved documents serve as the context for the generation-based model, which then generates a response based on the given context.
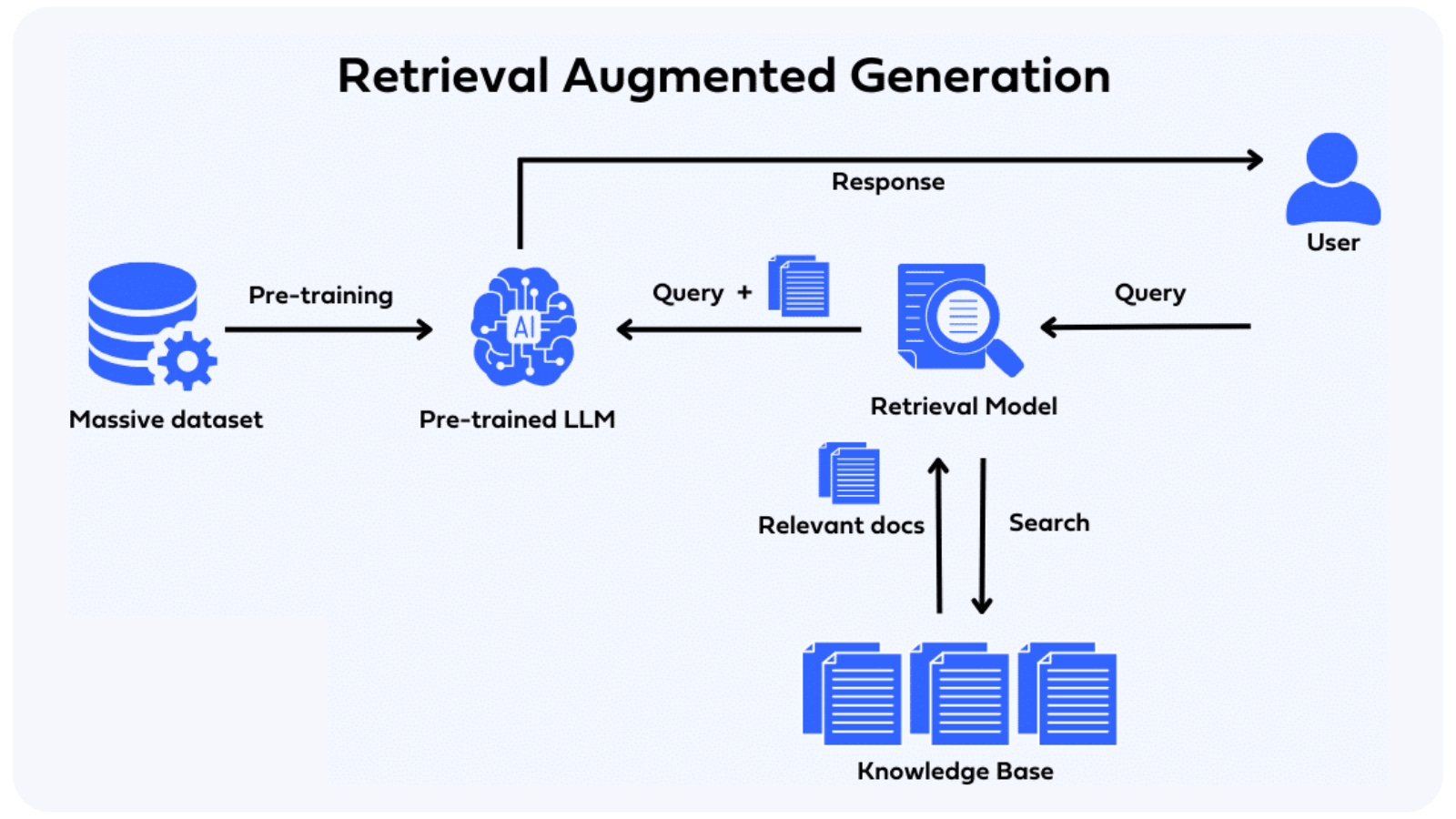
How does RAG work?
RAG acronym for Retrieval Augmented Generation works by integrating retrieval-based models with generative-based AI models. Retrieval-based models are true champions when it comes to gathering data from pre-existing online sources like newspaper articles, databases, blogs, and other knowledge resources such as Wikipedia or even internal databases. But they can’t produce original and unique responses. Inversely, Generation models can generate original and unique responses in the context of what is being asked but they find it difficult to maintain the accuracy in the output generated. So, both brothers came together and shook hands to combine their strengths and minimize their weaknesses. Now one brother finds relevant information from existing information sources while the other one takes the retrieved information, synthesizes it, and shapes it into a high-quality and contextually appropriate response.
How RAG will give Microsoft’s Search Engine (Bing) an edge over other search engines?
We generally search for information on proprietary search engines like Google or nowadays we’re using LLMs like Bard or ChatGPT to get to the point and accurate answers to eliminate the hustles of scrolling through tons of webpages present on the Internet. So, tech giant Microsoft just took a step to eliminate both of these challenges by implementing RAG into their AI-based search engine called Bing. And this gave them an edge to fight Google and ChatGPT at the same. You can experience Bing chat here.
Architecture of RAG
RAG has a unique architecture that utilizes a retrieval-based model and a generation-based model. The retrieval-based model is responsible for retrieving relevant documents or passages from a large corpus of text. These retrieved documents then serve as the context for the generation-based model, which generates a response based on the given context.
The retrieval-based model in RAG employs a technique called dense retrieval. This technique allows RAG to efficiently search through a large corpus of documents using dense representations like BERT embeddings. By using dense representations, RAG can quickly find relevant context and improve response generation speed.
To capture the semantic meaning of both the user's query and the retrieved context, RAG utilizes a bi-directional encoder. This encoder encodes the query and the context in both directions, allowing RAG to generate more accurate and contextually relevant responses.
Advantages of using RAG
When two brothers like retrieval-based models and generative-based models come together, they start delivering responses that are more accurate, relevant, and original while also sounding like they are curated via humans. That’s because RAG models can understand the context of queries and generate original and unique replies by combining the best of both models. With all these capabilities, RAG models are:
More Accurate and Enhanced Output
Getting Recent Information
Better at Synthesizing Data
Easier to Train
More Efficient and Decreased Hallucination
Conclusion
In Conclusion, RAG represents a significant advancement in language modeling by effectively combining retrieval and generation techniques. Its ability to retrieve relevant context from a large corpus of text and generate responses based on that context has proven to be highly valuable in applications such as chatbots and virtual assistants. RAG has the potential to greatly improve the user experience in various NLP applications.
If you have any concerns or questions, drop them in the comments below. If I wrote anything wrong or left out any important information, please clarify that below as well, would love your feedback and improvise in upcoming articles.
I'll be writing about more topics related to Artificial Intelligence and Machine Learning in future articles. If you find this insightful, join our network of AI & ML enthusiasts to connect, learn, and grow together 🌱.
AI Hallucinations
LLMs generate output based on statistics of related words and probability, they don’t have actual knowledge or consciousness. When LLMs are queried about nuanced topics or topics they’re not trained on they often try to make up answers on their own that are inaccurate or nonsensical.
These AI Hallucinations can generally have these causes:
Overfitting occurs when models are extremely complex or training data is especially noisy or insufficient in scope. The models learn the outliers and noise within the data, leading to low-quality pattern recognition, which in turn can lead to classification, prediction, and factual errors along with hallucinations.
Quality of training data issues include mislabelling, miscategorization, or bad classification of data, which can lead to AI bias, errors, and hallucinations.
Data Sparsity occurs due to a lack of fresh and relevant data to train the model, which can also cause hallucinations by encouraging the model to fill knowledge gaps on its own.